 ThinkBase
ThinkBaseUsing ThinkBase as a recommendation engine
ThinkBase has been used with a commercial project to recommend “collectible” objects to existing and new customers.
The details of the project are confidential, but it shares common characteristics with a range of applications driven by the desire of the customer to collect, whether porcelain, classic cars, stamps, coins etc.
The range of possible “collectible” objects in this project was very large, (> 100,000) with relatively few in stock at any one moment and limited, sparse purchase histories, and thus useful “shopping basket” data.
Knowing that collectors limit their collections to periods, countries, manufacturers and other more specific groupings, the major part of the work was to identify these groupings, and to further break these down into collectible sets. These might be Meissen porcelain figures from a particular year, Athenian Tetradrachms, 1960s Ferraris, etc.
So, as well as purchase history groupings and other groupings known from customer behavior, we needed to identify other “structural” sets of items we could recommend from.
This methodology has the benefit of the explainability that we look for in all uses of ThinkBase, in that we can justify recommendations. So rather than recommending item Y just because someone who had bought item X in the past had also bought item Y, we can recommend Y because the customer already had three elements of a set of five, and Y is one he or she didn’t have.
The data wrangling performed to prepare the data is very much domain and company IT dependent, but all “collectible” recommender systems will have common characteristics like the following:
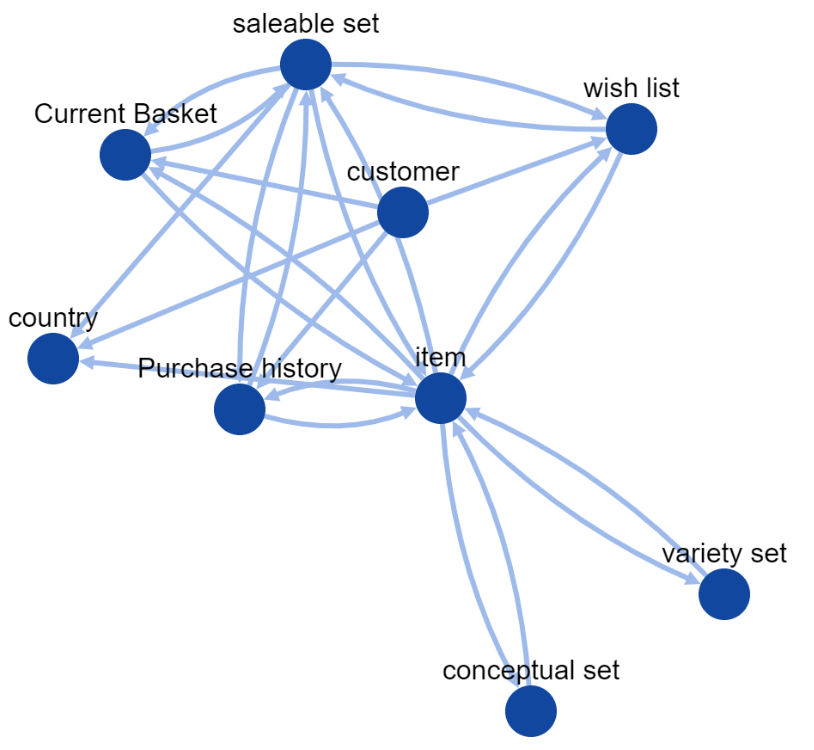
The above shows the top level “abstract” graph of the kinds of data items accessible to the analysis.
All the data items collected are examples of these objects and have only the relationships detailed in the graph.
Similarly, each node has a set of properties appropriate to its type and the data available, and properties of the Knowledge States are limited to these sets.
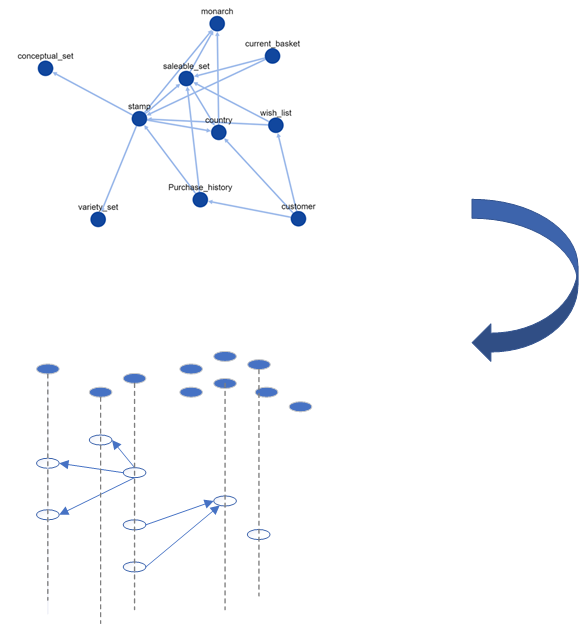
This diagram shows how data items, stored as "knowledge states" map onto the abstract graph description.
Given an item of a particular type, and wishing to recommend other items, we can search out from the item node via the various paths possible using the discover function and find items in the same groups to recommend.
Clearly, you may choose to weight different groupings differently, so that the order of recommendation can be adjusted over time.
This is achieved simply by adjusting the weights on the connections. Weights are treated as fuzzy truth values, representing the truth of the assertion “Recommendations found over this path are plausible.”.
A depth first search of the above graph won’t naturally terminate. A given item will be linked to several groups which are linked to several items, which are linked to several groups, and so on. A simple search will therefore possibly read out the entire contents of the knowledge states associated with it. In reality, we want to know the other items linked to a given item. Alternatively, given a customer, we may want to find linked items, or even similar customers. The solution to preventing searches beyond the nearest customers and items is to set a terminating ruleset on them in the graph.
This can be as simple as:
output categorical completed {true, false} complete;
if anything then completed will be true;
Loading recommender source data
Source data, as in machine learning and other such applications with ThinkBase, is loaded as Knowledge States.
Knowledge states inside the ThinkBase SaaS system are stored internally as json records in a high-speed cloud database, separate from the graph models.
Each data item in a knowledge state is linked back to the parent graph node using its ID, and similarly the presence of any connections is also linked to the parent connections.
For this project we loaded hundreds of thousands of items and set relationships as knowledge states, where each knowledge state was limited to hold just one node’s worth of data and the links to other knowledge states via their subject IDs.
This loading process is greatly facilitated by the ThinkBase Client which has a nuget package for .net applications here. See this open source project for help on building a data loader tool.
Using the recommender system in practice
Once the top level graph is created and the data is loaded, your ThinkBase project is a functional system. The most practical way to access it is via the GraphQL interface. Our darl.dev website contains a developer interface that you can use to experiment with programmatic access to ThinkBase.
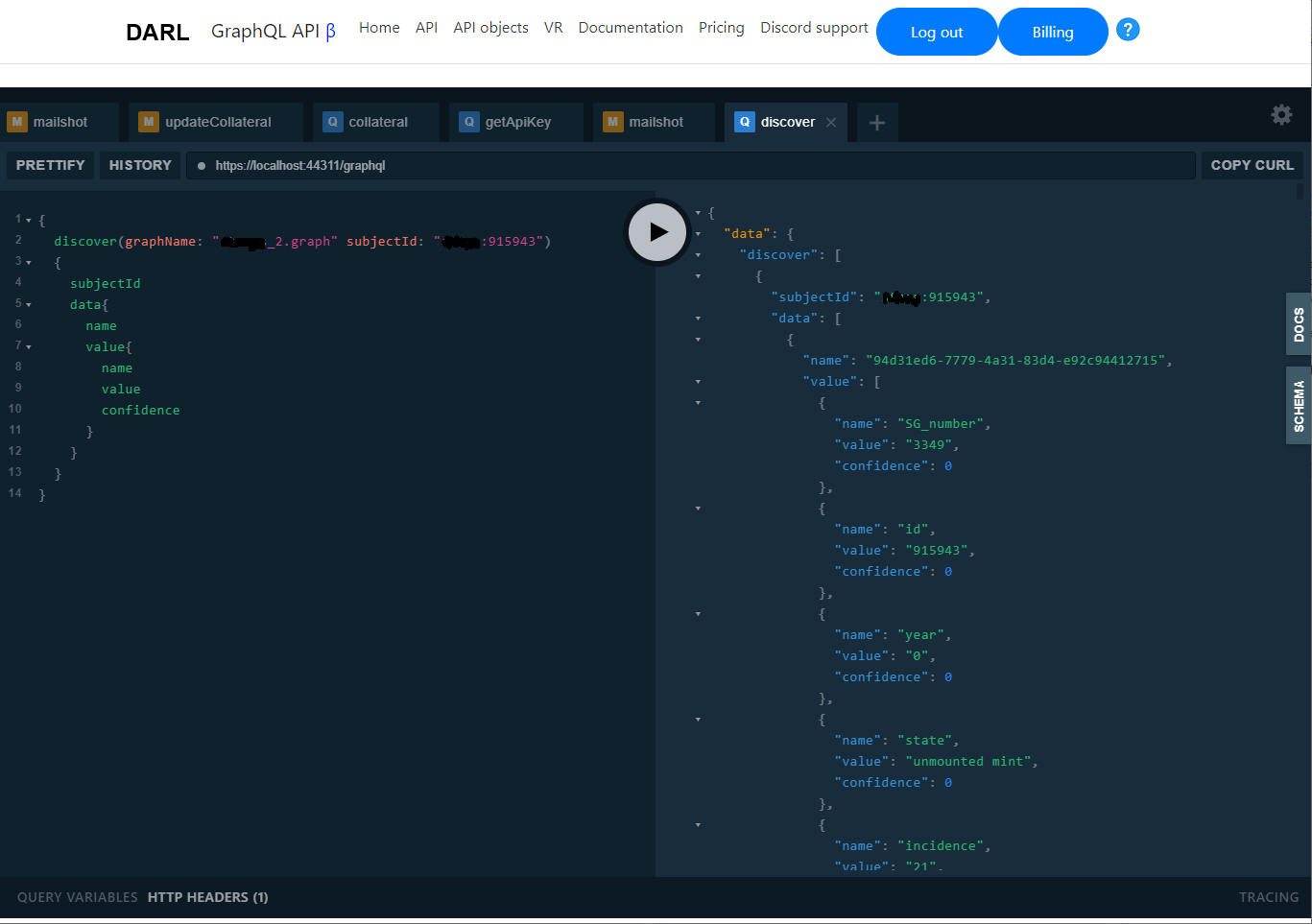
This shows a recommendation request accessing a pre-existing graph and choosing a known item as a starting point. The result, seen on the right, is a json encoded set of recommendations. The GraphQL interface returns the raw data of the processing results. It is up to the user to present these appropriately to the application, for instance in a web page.
ThinkBase's staff would be delighted to discuss this or any other kind of application of ThinkBase using the access methods below.